Hallucination LLM RAG RAG의 환각에 대한 대응 Written by Giljae Joo(주길재) in Hallucination, LLM, RAG with 댓글 없음 현 거대 언어 모델(LLM)은 지난 몇 년간 급격한 성장을 이루었습니다. 단순히 AI 모델을 사용하는 것을 넘어, 자사의 방대한 내부 데이터를 LLM에 연동하여 실질적인 비즈니스 가치를 창출하고자 하는 요구에 직면해 있습니다. 이런 배경에는 RAG(R... Read more
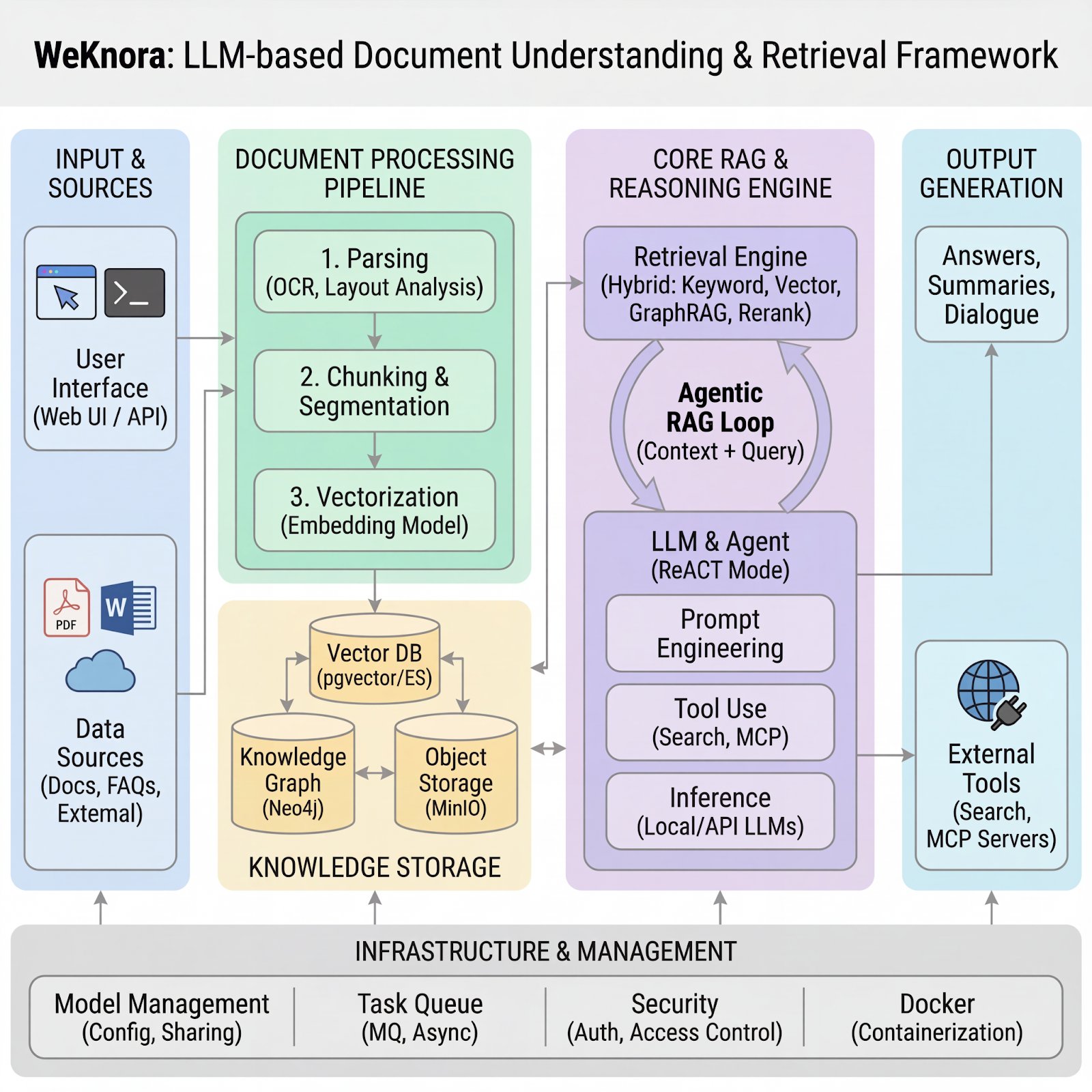
LLM RAG Tencent WeKnora WeKnora v0.2.0 런칭 Written by Giljae Joo(주길재) in LLM, RAG, Tencent, WeKnora with 댓글 없음 얼마전 Tencent에서 WeKnora v0.2.0을 런칭했습니다. 그런데 최근의 움직임과 약간 다른 느낌이 들었습니다. 최근 구글의 Gemini나 OpenAI의 모델들이 100만 토큰 이상의 방대한 컨텍스트를 한 번에 처리하기 시작하면서, 이제 RA... Read more