AI Data Labelling 데이터 라벨링, AI의 눈과 귀를 만들어주는 핵심 작업 7/16/2025, Written by Giljae Joo(주길재) in AI, Data Labelling with 댓글 없음 데이터 라벨링은 이미지, 텍스트, 오디오, 비디오와 같은 원시 데이터에 의미를 부여하는 중요한 과정이다. 아무것도 모르는 어린아이에게 사물을 가르치고 세상에 대해 이해하도록 돕는 것처럼, 인공지능(AI)과 기계 학습(Machine Learning)... Read more
AICC Contact Center AI Contact Center에 대한 단상 7/15/2025, Written by Giljae Joo(주길재) in AICC, Contact Center with 댓글 없음 요즘 여러가지 관점에서 다양한 것을 고민하고 있다. 그중 하나가 Contact Center이다. 현 트렌드는 AI 시대에 맞춰 AI Contact Center로 나아가는 듯 보인다. 나는 어떤 현상을 바라볼때, 긍정적인 면외에 부정적인 면도 함께 판단... Read more
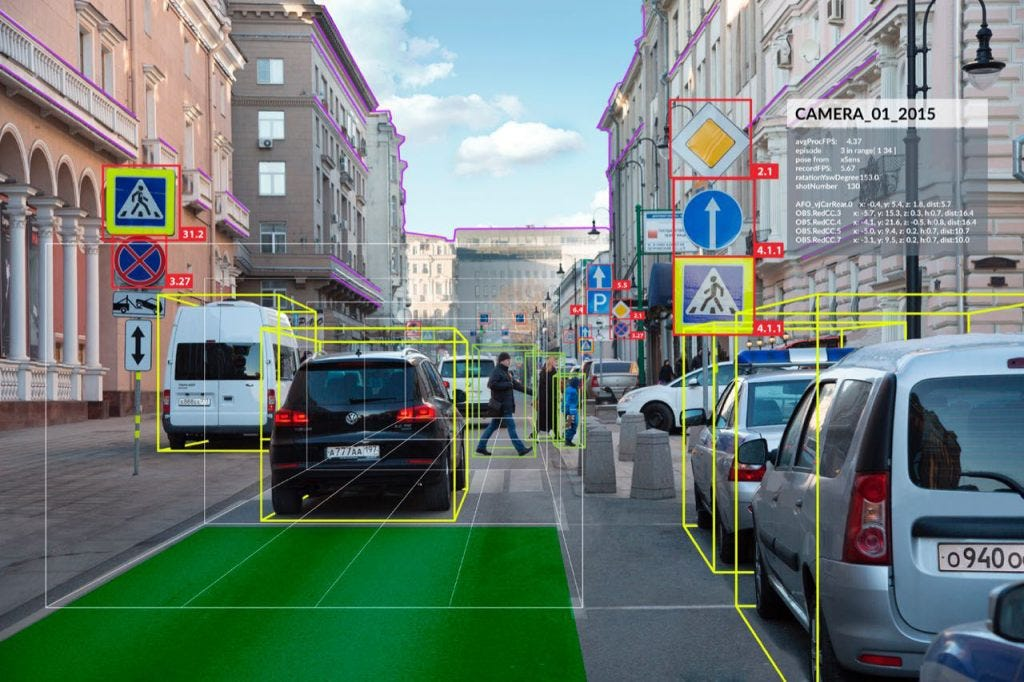
CNN Vision AI 컴퓨터 비전에서 일어나는 모든 일 7/14/2025, Written by Giljae Joo(주길재) in CNN, Vision AI with 댓글 없음 컴퓨터 비전에 대해서 요즘 관심이 많다. 과거에는 기계는 우리만큼 시각적 세계를 효율적으로 이해하지 못했다. 그러나 요즘은 상황이 다르다. 컴퓨터 비전은 컴퓨터가 이미지와 비디오를 시각적으로 어떻게 이해 할 수 있는지를 다루는 분야이다. 공학적 관점에... Read more
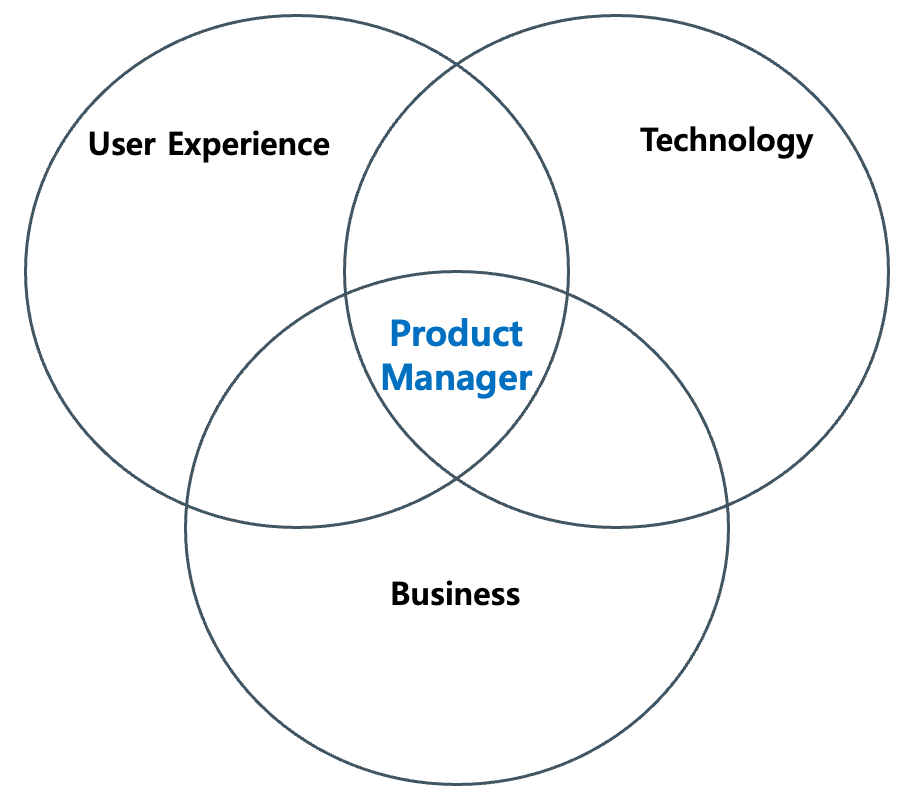
Product Manager Project Manager Product Manager vs Project Manager 7/08/2025, Written by Giljae Joo(주길재) in Product Manager, Project Manager with 댓글 없음 Product Manager(PDM)과 Project Manager(PJM)은 종종 혼동되는 역할이다. 본 글에서는 두 역할의 차이점을 설명한다. Product Manager는 무슨 일을 할까? PDM은 회사의 엔지니어링 및 사업 개발팀 그리고 고객과... Read more
회의 Meeting 회의 방식에 대한 생각 6/05/2025, Written by Giljae Joo(주길재) in 회의, Meeting with 댓글 없음 우리가 일을 할때 의사 소통 방식에는 두 가지 주요 방식이 있다. 첫 번째는 동기식 의사소통으로, 모든 이해 관계자가 동시에 상호 작용을 해야 한다. 이 방식은 대면 회의, 화상 회의, 전화 통화가 포함된다. 두 번째 방식은 비동기 방식으로, 발신자... Read more