Code formatting Hidden cost LLM 가독성의 은밀한 비용, 코드 포맷팅이 LLM 예산을 어떻게 소모하는가? 12/30/2025, Written by Giljae Joo(주길재) in Code formatting, Hidden cost, LLM with 댓글 없음 아카이브( arXiv.org )에서 흥미로운 논문 을 읽었고 내용을 정리해봅니다. 소프트웨어 엔지니어링 역사에서 “가독성”은 성역과도 같은 가치였습니다. 코드는 컴퓨터가 실행하기 위해 작성되지만, 인간이 읽기 위해서도 작성된다는 이야기가 많았지요. 그... Read more
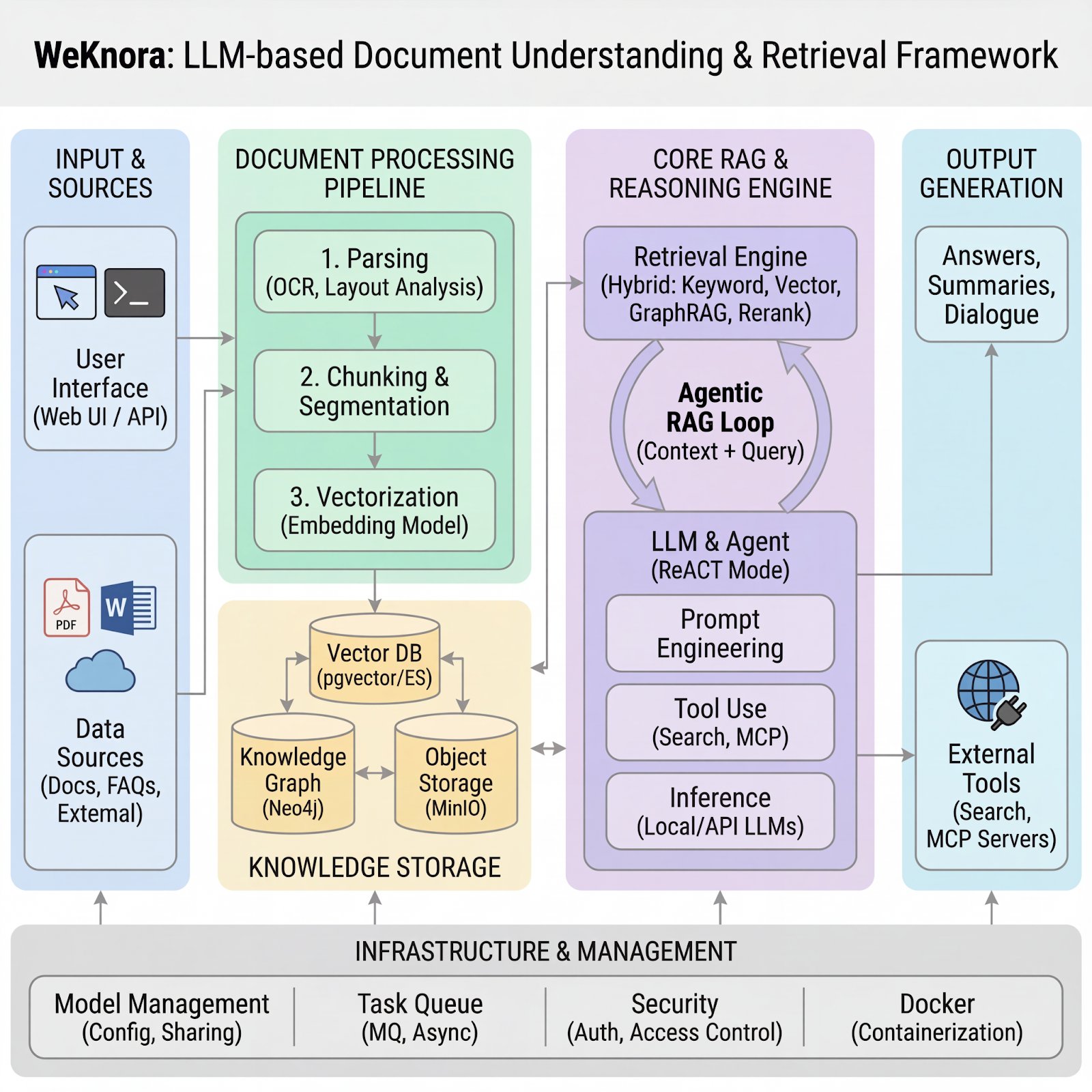
LLM RAG Tencent WeKnora WeKnora v0.2.0 런칭 12/24/2025, Written by Giljae Joo(주길재) in LLM, RAG, Tencent, WeKnora with 댓글 없음 얼마전 Tencent에서 WeKnora v0.2.0을 런칭했습니다. 그런데 최근의 움직임과 약간 다른 느낌이 들었습니다. 최근 구글의 Gemini나 OpenAI의 모델들이 100만 토큰 이상의 방대한 컨텍스트를 한 번에 처리하기 시작하면서, 이제 RA... Read more
DevOps IDP DevOps의 한계와 대안 탐색 12/22/2025, Written by Giljae Joo(주길재) in DevOps, IDP with 댓글 없음 약 15년전 등장한 DevOps는 철학이 매우 좋았습니다. 자동화, 지속적 통합(CI), 지속적 배포(CD)는 마치 모든 것을 해결해 줄 것처럼 여겨졌습니다. 하지만, 요즘은 DevOps는 실패했다. 혹은 DevOps는 허구다. 라는 냉소적인 목소리가... Read more
AX DX DX가 먼저인가? AX가 먼저인가? 12/07/2025, Written by Giljae Joo(주길재) in AX, DX with 댓글 없음 AI의 시대에 살고 있습니다. 그래서 요즘 “AI 우선”이라는 말이 유행처럼 번지고 있습니다. 일각에서는 “DX의 시대는 끝났다”고 얘기하기도 합니다. 그러나 현실은 복잡하고 이는 위험한 오해라고 생각합니다. 기존 시스템을 보유한 기업일 경우, 지속 ... Read more
Mistral3 Mistral 3 12/03/2025, Written by Giljae Joo(주길재) in Mistral3 with 댓글 없음 오늘 Mistral에서 4가지 새로운 모델을 출시했습니다. "Ministral" 소형 모델 시리즈(14B, 8B, 3B) 3가지와 매개변수 675B, 유효 매개변수 41B를 갖춘 Mistral Large 3 모델입니다. 위에서 언급한... Read more
Engineering Management 실리콘밸리가 말하는 엔지니어링 매니지먼트의 종말과 진실 12/02/2025, Written by Giljae Joo(주길재) in Engineering Management with 댓글 없음 2025년 현재, 불과 몇 년 전까지만 해도 개발자를 모셔가기 위해 사이닝 보너스와 최고의 복지를 내세우던 “채용 전쟁”은 옛 이야기가 되었습니다. 많은 이들이 “경기가 안 좋아서”라고 막연하게 말합니다. 하지만 우연히 읽게된 글에서 본 실리콘밸리의 ... Read more
AI AI Agent Design LLM UX Web AI가 읽는 제품과 서비스를 설계 11/29/2025, Written by Giljae Joo(주길재) in AI, AI Agent, Design, LLM, UX, Web with 댓글 없음 지난 30년 동안 웹의 역사는 인간을 위한 설계, 즉 “사용자 경험(UX)”의 역사였습니다. 1990년대의 투박한 텍스트 기반 인터페이스에서 매끄러운 모바일 터치 인터페이스에 이르기까지, 기술적 진보의 중심은 “인간의 눈과 손”이었습니다. 그러나 20... Read more
AEO AI GEO LLM llms.txt robots.txt SEO AI가 읽기 쉬운 Web을 위한 llms.txt 11/28/2025, Written by Giljae Joo(주길재) in AEO, AI, GEO, LLM, llms.txt, robots.txt, SEO with 댓글 없음 우리는 매일 웹사이트에 접속합니다. 화려한 디자인, 편리한 메뉴 구성, 광고 배너들이 우리를 반깁니다. 하지만 이 모든 시각적 요소들은 AI에게는 그저 소음에 불과하다는 사실을 알고 계셨나요? ChatGPT, Claude, Gemini와 같은 대규모 ... Read more
Agent AI Mode AI Model과 Agent 11/27/2025, Written by Giljae Joo(주길재) in Agent, AI, Mode with 댓글 없음 예전만 해도 우리는 AI에게 이렇게 말했습니다. “파리 가는 비행기 표 좀 찾아줘.” 그러면 AI는 친절하게 대답했죠. “여기 시간표 입니다. 예매는 링크를 눌러서 직접 하세요.” 하지만 위 대화는 완전히 변경되었습니다. OpenAI가 결제 기업 스트... Read more
머신러닝 프로그래머 학습 ML 머신 러닝을 시작하는 프로그래머가 저지르는 실수 11/05/2025, Written by Giljae Joo(주길재) in 머신러닝, 프로그래머, 학습, ML with 댓글 없음 머신러닝을 시작할 때 정해진 방법은 없습니다. 각기 다른 방식으로 배우고, 목적 그리고 목표도 다릅니다. 프로그래머가 머신러닝의 세계로 뛰어드는 것은 새로운 프로그래밍 언어를 배우는 것과는 다른 경험입니다. 논리와 명확한 규칙, 100% 예측 가능한 ... Read more
자기계발 누군가 내게 말해줬더라면 좋았을 것들 11/03/2025, Written by Giljae Joo(주길재) in 자기계발 with 댓글 없음 본 글은 샘 알트먼의 블로그의 " What I Wish Someone Had Told Me "의 글을 번역했습니다. 1. 낙관주의, 집착, 자기 믿음, 순수한 추진력 그리고 인맥은 일이 시작되는 방식이다. 2. 응집력 있는 팀, 침착... Read more
AI CLIP Huggingface NLI NLP Zero Shot 제로샷 학습 (Zero-Shot Learning) 10/23/2025, Written by Giljae Joo(주길재) in AI, CLIP, Huggingface, NLI, NLP, Zero Shot with 댓글 없음 본 글은 제로샷 학습(Zero-Shot Learning)의 개념을 이해하고, 실제 예제 코드를 통해 이를 구현하는 방법을 설명합니다. 제로샷 학습이 무엇이고, 왜 중요한지를 Hugging Face를 이용해 얼마나 쉽게 활용할 수 있는지 다루도록 하겠습... Read more